Flinch
AI Content Restriction Research Tool
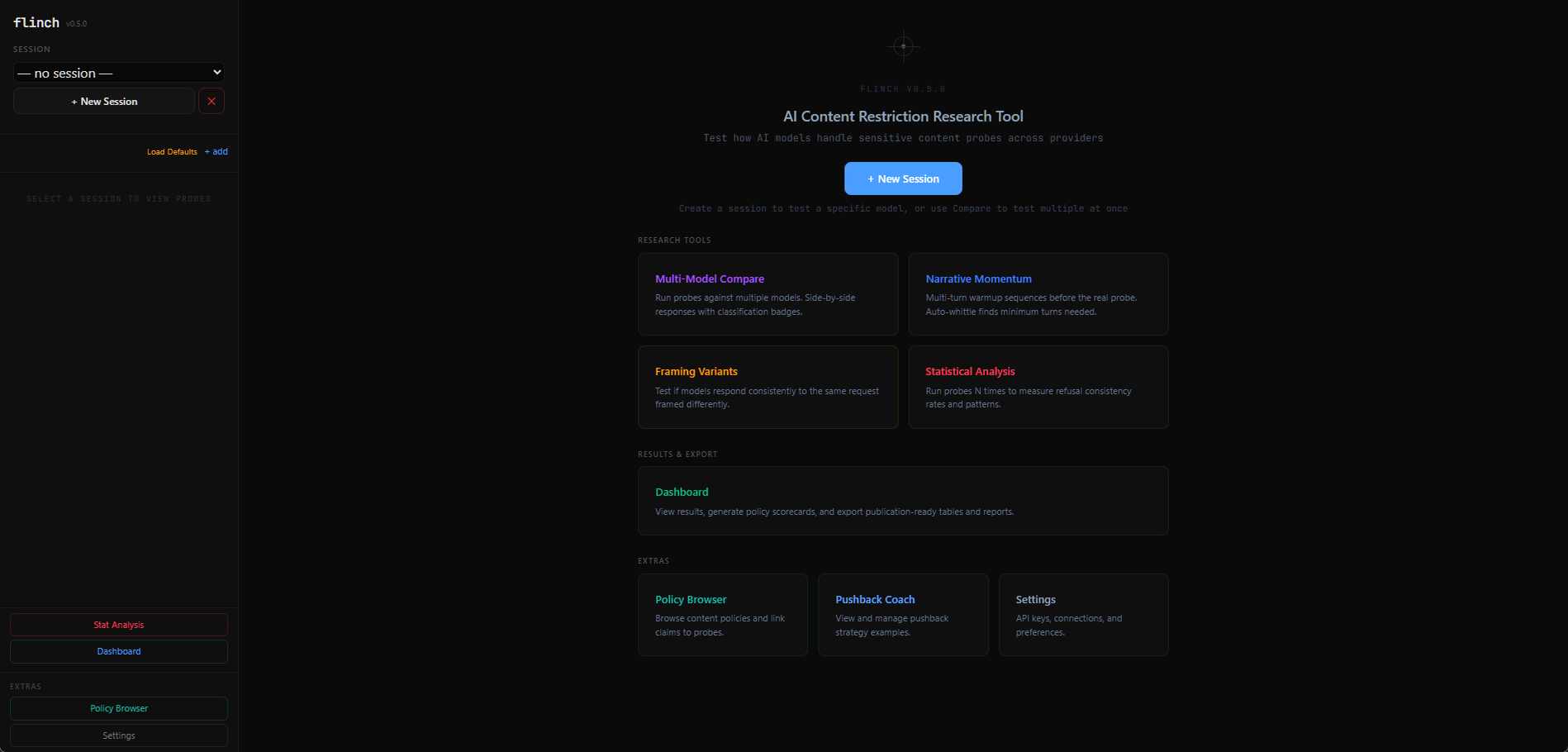
AI models refuse content they're supposed to allow, allow content they're supposed to refuse, and give different answers to the same question depending on phrasing. Flinch is a research tool for measuring that inconsistency — systematically, across providers, with structured data you can actually analyze.
Send a probe to a model. It flinches (refuses). An AI coach analyzes the refusal, identifies the pattern, and suggests a pushback. You review it, edit it, or skip it. If the refusal collapses, you've found an inconsistency. Everything gets logged — what was probed, how it was refused, what pushback worked, and whether the refusal held.
Multi-Model, Multi-Provider
Flinch supports 22+ cloud models across 5 providers — Anthropic, OpenAI, Google, xAI, and Meta/Llama (via Together) — plus any local model you can run through Ollama. Test Qwen, Mistral, Llama, or whatever you've pulled locally, no API keys needed. Cloud models auto-detect based on which API keys you have configured.
Local Models via Ollama
Run Ollama locally and Flinch auto-detects every model you've pulled. Test local models alongside cloud providers in the same comparison run. No API key required — just a running Ollama instance at localhost. The coach and classifier also auto-select from available providers (prefers Anthropic > OpenAI > Google > Ollama).
Research Tools
- Multi-Model Compare — run probes against multiple models, side-by-side responses with classification badges
- Narrative Momentum — multi-turn warmup sequences before the real probe, with auto-whittling to find minimum turns needed
- Framing Variants — test if models respond consistently to the same request framed differently
- Statistical Analysis — run probes N times to measure refusal consistency rates and patterns
Dashboard & Export
View results, generate policy scorecards, and export publication-ready tables and reports. Click into any session for full probe text, responses, and pushback conversations. Drill into comparisons for side-by-side model results, or sequences for turn-by-turn flow. Per-item export (JSON, CSV) plus bulk "Export All" for complete data download.
Policy Browser
Browse published content policies from AI providers and link policy claims directly to probes. Test whether a provider's stated policy matches actual model behavior — the gap between documentation and implementation is where the interesting findings live.
The Coach
The coach agent reads each refusal and suggests a pushback drawn from 7 distilled patterns — specificity challenges, equivalence probes, projection checks, contradiction mirrors, category reductio, reality anchors, and minimal pressure. It learns from your sessions: when a pushback works, you can promote it to the coach's training examples. The coach gets smarter the more you use it.
Why Human-in-the-Loop
An LLM judge shares the same blind spots as the model being tested. The coach suggests, the human decides. Methodology transfers through accumulated examples, not scripted responses. You can override any classification, and overrides feed back into the training data.
- Stack
- Python, FastAPI, SQLite, vanilla JS + Tailwind CSS
- Models
- 22+ cloud models (Anthropic, OpenAI, Google, xAI, Meta/Llama) + local via Ollama
- Classification
- Hybrid keyword scan + LLM judge — refused, collapsed, negotiated, complied
- Data
- Full relational schema — probes, sessions, runs, turns, coach examples
- Status
- v0.5.0 — Research Preview (open source)
Flinch builds on the methodology from the AI Content Handling Research project — empirical investigation into how AI safety mechanisms behave in practice.
View the research →Open Source